Overview
Micro-Specialization uses relation- and query-specific
information to specialize the DBMS code
at runtime based on identifying runtime invariant. Runtime invariant is often
of the form of variables in code that hold constant values during code
execution. Micro-specialization is applied to eliminate from the original
program unnecessary code such as branching statements that reference runtime
invariant in branch-condition evaluation. The resulting specialized code
greatly reduce the code complexity as well as significantly improve the
runtime
efficiency during code execution.
We have developed a taxonomy of approaches and
specialization times and
identified a general
architecture that
isolates most of the
creation and execution
of the specialized code in a DBMS-independent module.
We have realized a prototype of this module in PostgreSQL. Micro-specialization focuses on low-level invariant present in code. Hence micro-specialization does not affect the existing architecture of the DBMS nor the query evaluation algorithms. Rather, micro-specialization preserves the generality and wide applicability of the DBMS.
Experiments have shown that with just a few micro-specialization instances applied within PostgreSQL, performance of the DBMS across bulk-loading, complex analytic queries, and random modifications was significantly improved. For TPC-H, per-query execution time was improved by up to 33%, with an average improvement across all queries of over 12%. For TPC-C, throughput improvements exceeding 11% were observed. Each additional micro-specialization should result in further improvement in performance.

Publications
• R. Zhang, R. T. Snodgrass, and S. Debray, Micro-Specialization in DBMSes,
in Proceedings of IEEE International Conference on Data Engineering
(ICDE), April 2012. (12 pages) [PDF]
• R. Zhang, S. Debray, and R. T. Snodgrass, Micro-Specialization:
Dynamic Code Specialization of Database Management Systems,
in Proceedings of IEEE/ACM International Symposium on Code
Generation and Optimization
(CGO), March 2012. (11 pages) [PDF]
• R. Zhang, R. T. Snodgrass, and S. Debray, Application of
Micro-Specialization to Query Evaluation Operators,
in Proceedings of IEEE International Workshop on Self Managing Database
Systems (SMDB2012, In conjunction with ICDE 2012). (7 pages) [PDF]
Dissertation
Rui Zhang, Micro-Specialization: Dynamic Code Specialization in DBMSes,
Department of Computer Science, University of Arizona, 2012. [PDF]
People
Directors:
Richard T. Snodgrass
Saumya Debray
Rui Zhang
(Dataware Ventures)
Chief Programmer History
Wei
He (?? - present)
Jennifer Dempsey (Spring 2014 - ?)
Young-Kyoon Suh (Fall 2012 - Fall 2014)
Rui Zhang (Spring 2010 - Spring 2012)
Graduate Student:
Wei He
Previous Graduate Students:
Wallace Chipidza
Devesh Chourasiya
Jennifer Dempsey
Benjamin Dicken
Anisha Goel
Saurabh
Maniktala
Rui Zhang
Yi Zhang <
Previous Undergraduate Students:
Troy L. Bowman
Dylan Howard
Cody Mingus
Current Research
We are investigating approaches to automating the application of
micro-specialization to a variety types of DBMSes as well as to many components
within particular DBMSes. Specifically, we are developing a set of
tools termed
Highly Integrated deVelopment Environment(HIVE).
HIVE can greatly reduce the effort for developers to
apply micro-specialization manually, hence improving
the efficiency of applying micro-specialization
aggressively.
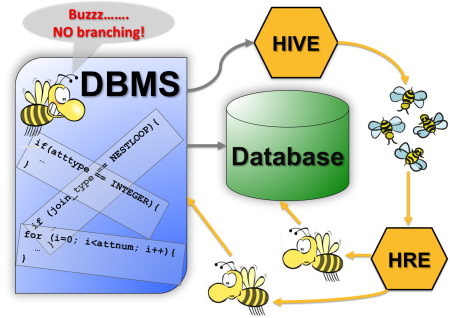
In the figure on the right, HIVE reads and analyzes
the object code of the DBMS to identify invariants
which are mapped back into the source code.
Short segments of the source code are converted
into proto-bees (shown on the right of the
figure). These proto-bees are then instantiated
by HIVE-Runtime Environment (HRE) into the bees
(shown in the bottom of the figure) which are then
executed by the DBMS and can also be associated
with data within the database. These bees eliminate
unnecessary branches because each is tailored to
a particular value of the invariants.
Funding

|
III:
Small: Extending and Automating Dynamic Specialization of
Database Management Systems
National Science Foundation, CISE IIS-1318343 Information and Intelligent Systems Division September 2013 to August 2016 (Richard T. Snodgrass, PI with Saumya Debray, co-PI) |
Acknowledgements
Webmaster: Rick Snodgrass