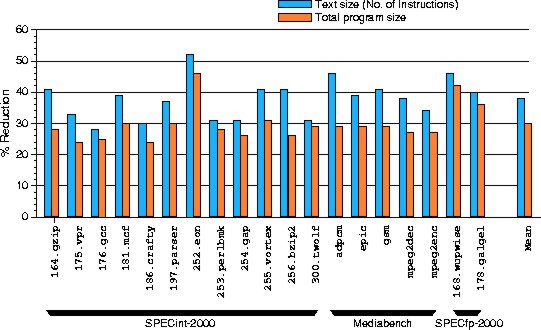
The programs were compiled with the vendor-supplied compilers (cc V6.1-011; C++ V6.2-024; DIGITAL Fortran 77 v5.0) at optimization level -O2, with additional linker options to produce statically linked executables containing symbol and relocation information (the requirement for statically linked executables is a result of the fact that squeeze uses relocation information to distinguish addresses from data; the Tru64 Unix linker does not retain relocation information for executables that are not statically linked). The optimization level chosen ensures that the compiler carries out all optimizations except for those, such as loop unrolling and function inlining, that can increase code size.
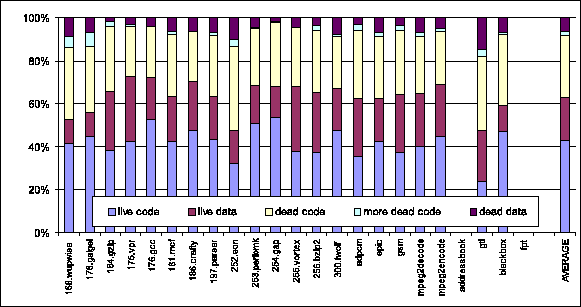
The following diagram gives a breakdown of where our code size savings come from:
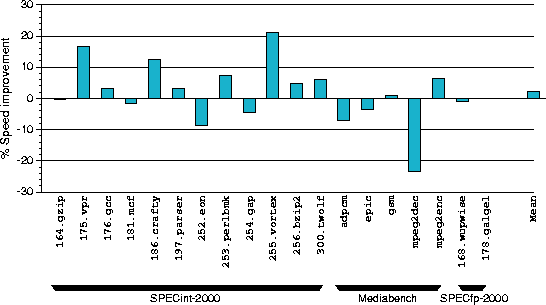
The timings were obtained on a 500 MHz Compaq Alpha 21164 EV56 processor with a split primary direct mapped cache (8 KB each of instruction and data cache), 96 KB of on-chip secondary cache, 8 MB of off-chip backup cache, and 512 Mbytes of main memory, running Tru64 Unix 5.0a.
While some programs, such as the mpeg2dec program from the Mediabench benchmark suite, suffer a performance degradation, many of the programs actually run faster after compaction. For example, the 255.vortex program from the SPEC-2000 benchmark suite speeds up by over 20%. On average, our collection of benchmark programs experiences a 2% speed improvement due to squeeze. There are two reasons for this performance improvement. First, a significant portion of the code size reduction is due to aggressive inter-procedural optimizations that also improve execution speed. Second, transformations such as profile-directed code layout, which need not have a large effect on code size, can nevertheless have a significant positive effect on speed.