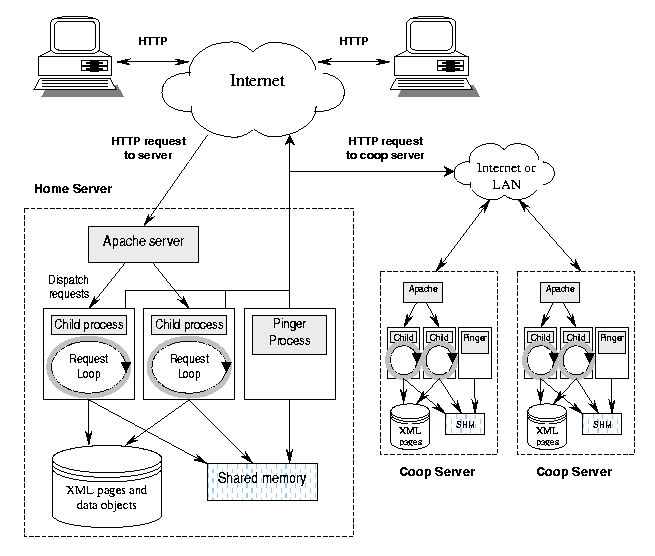
Figure 1: Functional diagram of DCWS system.
Contents:
The DC-Apache module is implemented using the API and the module interface provided by Apache. The Apache's module interface can let us insert several processing handlers into the Apache server's request processing cycle, which is divided in several phases. The DC-Apache module then uses those handlers to process incoming connection requests.
Figure 1 shows the DC-Apache system's functional
structure. The Apache server's main process dispatches request to several
child processes. Each child process servers the request in a request loop
divided in several phases as described before. Using the handler mechanism,
we implemented the DC-Apache system as an Apache module that processes
request in the request loop. The "pinger" process's function is to
compute and collect load information about participating servers. The share
memory contains the document graph and statistics information.
DC-Apache Module configuration directives:
The DC-Apache module gets its configuration information from the Apache's configuration file. The DC-Apache module introduced three new directives: ExportPath, ImportPath, Backend and DiskQuota.
Document Migration and Replication:
Document migration and replication mechamism is shown by the following figures:
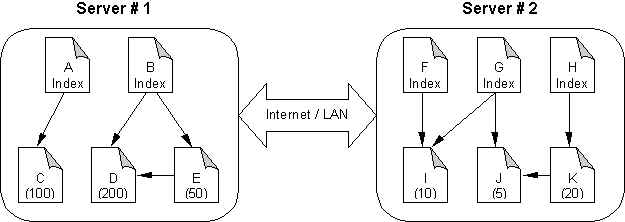
Server #1 is overloaded, we want to move some documents to server #2.
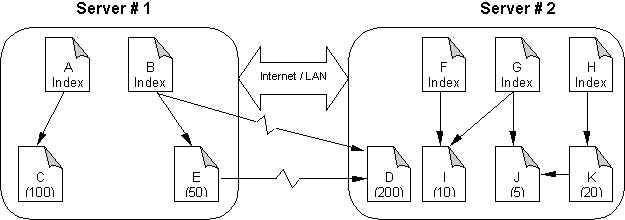
Document D has been chosen to migrate to server #2, because it's most effective: quick balancing with minimum data transfer. Two hyperlinks should be modified. Clients see the new URL and will access the new server.
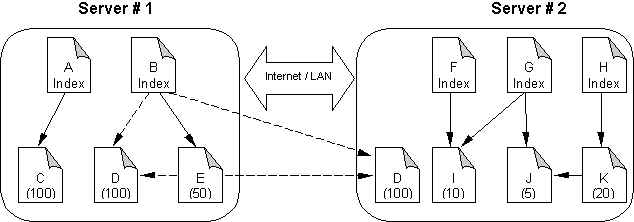
Document D can
also be chosen to be replicated to server #2. There are two choices for
hyperlinks in B and E pointing to D. We can dynamically choose one hyperlink,
according to current load state.
Load Balancing and Consistency:
In DC-Apache module, we store the replication information inside the shared memory and let the home server dynamically generate the hyperlinks when serving the request. To enhance the processing speed, we do not parse a document on every request, instead we parse the document at the time of building the document graph and before the server starts to serve requests. We can store the hyperlink information in the document graph: just associate this hyperlink with its length and start offset in the document. With this position information, when we send a request's response, if one hyperlink needs to be dynamically generated ( the document this hyperlink pointed to has copies on coop servers ) we substitute the hyperlink part in the file with generated URI according to the replication information in the shared memory, and skip the hyperlink part in the file.
This also gives us a better chance to do dynamic
load balancing. We can generate hyperlinks according to the current load
information and try not to generate hyperlinks pointing to the heavily
loaded server.
Experimental Environments
We tested the Apache server with DC-Apache module on a cluster of 64 Intel Pentium workstations. Every workstation has a CPU of 200 MHz clock rate and 128MB memory. The operating system is Red Hat Linux release 5.1 (Manhattan) Kernel 2.0.34. They are all connected by a Catalyst 5500 switch, which provides a 100Mbps switched Ethernet network. One workstation is used as control machine. The Apache servers can be running on 16 workstations, so the server number is from 1 to 16. The rest 32 workstations are for test clients.Results
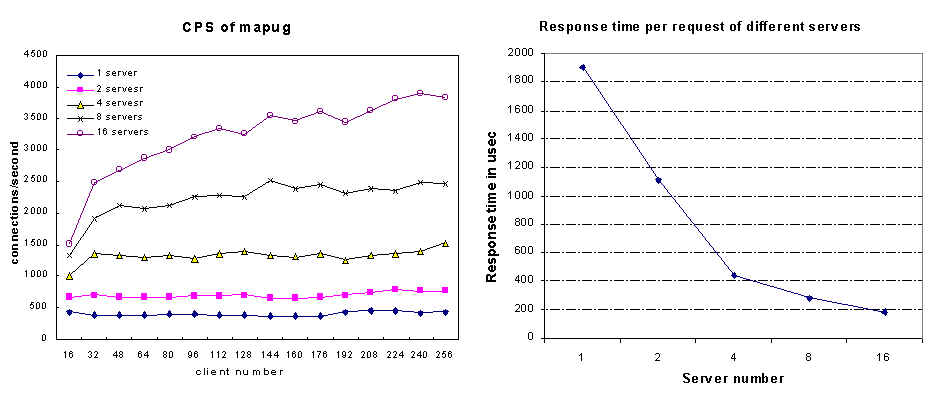
We did the experiments using client number from 16
to 256 with increment of 16. The data is gathered from the client side.
The result of Sequoia data set ( without hot spot
) is shown below:
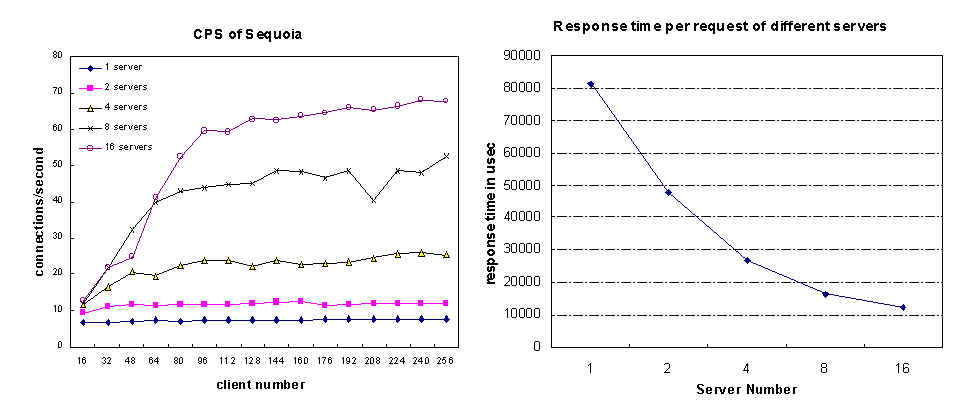
The result of data set Mapug ( with host spots ) is shown below: