length is a function from lists of elements
of some (unspecified) type a, to integer. I.e.
it doesn't matter if we're taking the length of a list
of integers or a list of reals or strings, the
algorithm is the same.
Note that head and tail always
take a list as their argument. tail
always returns a list, but head can return any
type of object, including a list.
Note that it is because of Haskell's strong typing that
we can only create lists of the same type of element.
If we tried to do
the Haskell type checker would complain that we were
consing an Int onto a list of Bools, while the type
of ``:'' is
Obviously remdups should work for any list, not
just lists of Ints. Removing duplicates from a list
of strings is no different from removing duplicates
from a list of integers.
However, there's a complication. In order to remove
duplicates from a list, we must be able to compare
list elements for equality.
The polymorphic type
is therefore a bit too general, since it would allow
any type, even one for which equality is not defined.
Haskell uses context predicates to restrict
polymorphic types:
Now, remdups may only be applied to list of
elements where the element type has == and
= defined.
Eq is called a type class. Ord
is another useful type class. It is used to
restrict the polymorphic type of a function to
types for which the relational operators
(<, <=, >, >=) have been defined.
We want to define functions
that are as reusable as possible.
Polymophic functions are reusable
because they can be applied to arguments
of different types.
Curried functions
are reusable because they can be specialized;
i.e. from a curried function f we can create a
new function f' simply by ``plugging in'' values
for some of the arguments, and leaving others
undefined.
Let f be a function from Int
to Int, i.e. f :: Int -> Int.
Define a function total f x so that
total f is the function which at
value n gives the total f 0 + f 1 + + f n.

![\begin{gprogram}
length [1,2,3] \xxxxxxx $\Rightarrow$\ 3 (list of Int) \\
le...
...g) \\
length ''Hi!'' \xxxxxxx $\Rightarrow$\ 3 (list of Char)
\end{gprogram}](img3.gif)
![\begin{gprogram}
remdups [1] \xxxxxxx $\Rightarrow$\ [1] \\
remdups [1,2,1] \...
...\ [1,2,2] \\
remdups [1,1,1,2] \xxxxxxx $\Rightarrow$\ [1,2,1]
\end{gprogram}](img8.gif)
![\begin{gprogram}
remdups :: [Int] -> [Int] \\
remdups x:y:xs = \\
\x if x == y...
...arrow$\ case 2 \\
remdups xs = xs \xxxxxxxx $\Leftarrow$\ case 3
\end{gprogram}](img9.gif)
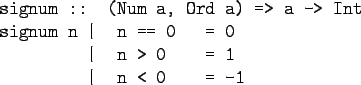
![\begin{gprogram}
\redtxt{? copy 5 ''five''} \\
\x [''five'',''five'',''five'',\...
...
\redtxt{? copy 5 (dup 5)} \\
\x [(5,5),(5,5),(5,5),(5,5),(5,5)]
\end{gprogram}](img15.gif)
