While it is tempting to view paths as an optimization that can be super-imposed on an existing layered system---and it is certainly the case that many of the ideas described in this paper can be applied in this way---we take a more ``first principles'' approach to defining paths. Specifically, this section develops a working definition of paths in an incremental fashion. Our goal is to explore the design space for paths, and in the process, to introduce the particular architecture that we settled on.
A path is a linear flow of data that starts at a source device and ends at a destination device. While the data is moved from the source to the destination, it is transformed (processed) in some path-specific manner. That is, if the input data is represented as a message m, then the output message is g(m), where g is the function that represents the path-specific transformation. In addition, each path has two queues associated with it, as depicted in Figure 2, thereby decoupling the input and output devices. A path scheduler determines when a given path is executed, that is, when g(m) is evaluated.

While paths connect devices, there is no direct relationship between device pairs and paths: a given device pair can be connected by zero or more paths. Allowing for multiple paths to connect the same pair of devices is sensible since both g(m) and the scheduling priority may vary. For example, one path may handle UDP packets, whereas another may handle TCP packets. Similarly, two paths that forward IP packets between a pair of devices may need to be scheduled differently if they provide a different quality of service. Thus, paths are dynamic entities that are created at runtime; there is no a priori limit on the number of paths that can exist in a given system.
What are the properties of basic paths? First and foremost, once a message has been enqueued on the input queue of a path, it is already known what device the (possibly transformed) output message will arrive at. For the purpose of resource management, it is also known that m belongs to the path on which it is enqueued, and all execution is performed on behalf of that path. In other words, knowledge is available early and globally.
The key problem in creating a path is how to specify g(m). While it would be possible to write a specific function for each path with distinct functionality, it is more convenient to derive g(m) automatically from a modularly organized system. This is because many of the paths are likely to have substantial functionality in common, such as various network, file, and windowing protocols. Generating a path from components does not preclude writing a specialized g(m) for those cases that warrant the extra effort.
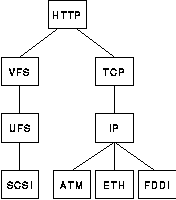
A router graph represents the modular structure of the system, where each router is a software module that implements a specific task, such as the NFS protocol or a SCSI driver. The reason we call these modules routers will become clear in a moment. As is common in a modular/layered system, individual routers provide their functionality based on the functionality of other routers, that is, it is possible to draw a dependency graph that represents the interdependence among the various routers. This also means that a router graph fully describes what kind of tasks a given system can perform. For example, Figure 3 depicts a router graph that could be used to implement a web server. Given this graph, a path that starts at the ETH router (Ethernet device) and ends at the SCSI router (disk device) would have a g(m) that is the composite of the functions contributed by each router; i.e.,
[Eq.
However, this still begs the question of how a path is created. There are essentially two approaches: (1) the path is pre-specified externally, and (2) the path is discovered incrementally. This division corresponds to the two sources of ``knowledge'' that influence path creation: global and router-specific. Global knowledge is of the sort ``for a web service, the following sequence of routers need to be part of the path.'' Global knowledge may also be used for optimization, for example, there may be an optimized g(m) available for the web path that is preferred to an automatically derived composite function. In contrast, local knowledge is of the form ``if invariant X is true for the path under construction, then the path can pass through this router'' or ``if invariant Y is false, then the path cannot go beyond this router.''
Using global knowledge alone to create a path would be difficult since this knowledge often requires familiarity with the internal workings of the routers that are traversed by a path. In contrast, creating a path based on router-specific knowledge alone would limit the utility of paths considerably. (Recall that most advantages of paths are due to the global knowledge they afford).
In our path architecture, paths are created in two phases. First, router-specific knowledge is used to create a maximum length path. Second, this maximum length path is transformed (optimized) using global transformation rules, each of which is defined by a < guard, transformation> pair. If the guard evaluates to TRUE, the corresponding transformation is applied, resulting in a new path. This process repeats until all guards evaluate to FALSE.
To better illustrate the difference between local and global knowledge, consider the router graph given in Figure 3. Suppose there is a path that starts at SCSI and ends at ETH. Such is the case, for example, if IP can determine that the remote host is on the same Ethernet as the local host. If this is not true, then IP can not be sure whether data will go out through ATM or FDDI, since the routing tables may change in the middle of the data transfer. Clearly, this decision is completely IP specific, that is, based on local knowledge. On the other hand, there are several global facts that hold for a web path that could be exploited, for example, data is transfered through TCP in a predominantly uni-directional manner and accessed on the disk in a strictly sequential fashion. Note that each such invariant may affect the function gi of one or more other routers. For example, the fact that data is accessed sequentially may mean that it is best to avoid caching in the file system (UFS). Similarly, the fact that TCP is in the path may mean that the IP fragmentation code can be omitted completely.
Finally, note that our definition of a path's semantics, which we denote as g(m), should not be taken to mean that procedures constitute the fundamental building blocks of paths. It is equally legitimate to construct a path from a sequence of basic blocks, which is more in line with having the path abstraction represent the ``fast path'' through the system. In fact, procedures and basic blocks define two ends of a granularity spectrum. Scout implements a specific point on this spectrum, as described in Section 3.
We motivated routers as a means to automatically derive the path function g(m). Alternatively, a router graph can be viewed as a set of interconnected nodes that forward messages along their links in the dependency graph. The operation of a router is to receive a message, process it, and then forward the resulting message to another router, as illustrated in Figure 4.
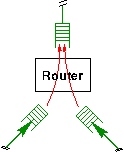
If a message is injected at some router, the trail it leaves in the router graph as it is processed and forwarded corresponds to a sequence of routing decisions. If a given trail is used very often, it may be worthwhile to explicitly encapsulate and optimize it. This is exactly what a path does: it represents a fixed sequence of routing decisions through the system's modules. This is not unlike a virtual circuit through a network: at connection establishment time, a set of invariants that are guaranteed to hold for the duration of a connection is specified. In return, these invariants permit the customization of the path in a way that is optimized for that particular connection. In the case of a virtual circuit, the set of invariants contains the address pair of the communicating peers, but it may include other parameters such as the desired quality of service. The same kind of invariants are useful for creating paths. For example, knowing what quality-of-service a path requires helps when choosing an appropriate scheduling policy and priority.
In this context, it makes more sense to let paths connect an arbitrary pair of routers rather than insisting that a path connects a pair of devices. The latter case is ideal in the sense that it provides a maximum amount of global knowledge. However, the maximum length of a path is related to the strength of the invariants. In general, the stronger the invariants, the more routing decisions can be frozen at path-creation time, and the longer the resulting path. While it is preferable to have long paths, a general model must allow for the degenerate case where invariants are so weak that not a single routing decision can be made at path creation time. This degenerate case roughly corresponds to a traditional layered system.
As defined so far, paths are simple and highly predictable: a message arrives at the input queue, the path is scheduled for execution, and the transformed message is deposited in the output queue. While this simplicity is ideal for the purpose of optimization, it also limits the usefulness of paths. Since it is our goal to define paths in a way that moves them from a purely performance-motivated concept into an abstraction with which a complete operating system can be built, we must extend paths to make them more widely applicable, but in a way that does not destroy the properties that make the path abstraction attractive in the first place.
Processing in a path is usually bi-directional: a remote-procedure call arrives over the network, results in some computation, and an answer is sent back to the caller; the arrival of a network packet triggers the sending of an acknowledgment; or a disk block is requested and arrives asynchronously. Such bi-directional paths could be handled by creating two separate paths, but it seems more natural if a path that is used to make a request is also the one that yields the response. A similar argument can be made about resource management. A more technical argument for making paths bi-directional is that often the two directions are dependent on each other. For example, when sending a network packet to a remote host, it may be desirable to include a piggy-back acknowledgment in that same packet.
Therefore, we extend the path model as follows. Each path end has a pair of queues---an input queue for one direction, an output queue for the other direction. The path function g(m) is also extended to take a second argument d that gives the direction (FWD or BWD) in which the path should be traversed. FWD is the direction in which the path was created, while BWD refers to the reverse direction. Each router-specific function is extended in the same way.
The current path model assumes that the path transformation is ``work-preserving,'' that is, for every input message, there is exactly one output message. This is limiting since it means that important operations such as packet reassembly and fragmentation cannot be accommodated. In the former case, most input messages do not result in an output message. Instead, the partial messages are buffered inside the router. In the latter case, every input message may result in many more than one output message. Similarly, a retransmission timeout may result in a new message being generated spontaneously from within the path.
For this reason, we loosen the evaluation rule for paths. Suppose that creating a path results in the routers contributing the functions g1, ..., gn. A message may now be injected at any one of these sub-functions and the invocation of gi may result either in gi-1 or in gi+1 being invoked. That is, these sub-functions can be invoked in any order, subject to the rule that only neighboring functions are invoked, or that the message be enqueued at an output queue.
In summary, a path is created incrementally by invoking a create operation on a router and specifying a set of invariants. The invariants describe the properties of the desired path, and are used to determine a next router that must be traversed by any message traveling on this path. The path reaches its maximum length when the invariants are no longer strong enough to make a unique routing decision. Each traversed router contributes a function gi that is applied when processing a message. A path that traverses three routers is shown in Figure 5.

Path execution is decoupled from the arrival and departure processes at the routers by four queues. For each direction, there is an input and an output queue. Typically, a path execution involves dequeuing a message from an input queue and evaluating the gi functions in sequence until the other end of the path is reached. However, for generality, a message may get absorbed in the middle of a path, or turned around, or a new message may be created spontaneously inside a path.
Finally, keep in mind that policy issues---i.e., how to use paths for a given system---remain unspecified. There are two dimensions to this issue, which can be visualized as the ``length'' and the ``width'' of the path, respectively. The ``length'' of the path is simple to understand: it corresponds to the number of routers that the path traverses. A path's width is more subtle: a highly specialized path is narrow, whereas a more general path is wide. For example, a path that can only be used to carry non-fragmented messages for a specific host-pair would be considered narrow, while a path from a network adapter to the IP protocol that can handle any IP datagram would be considered wide.
While it might seem that one wants paths to be as narrow (specific) as possible, this is not necessarily the case. Such a strategy can lead to an explosion of paths---e.g., one per packet or one per request/response transaction---which also implies having to create paths too frequently. Since there is a cost associated with path creation, one clearly wants the path to have enough breadth to carry multiple messages. The strategy we have adopted is to define a modest number of long-lived paths (e.g., one per window, one per open file, one per TCP connection) and then to define a small number of ``short/fat'' paths to catch the exceptional cases (e.g., all fragmented IP packets).