This section sets the context in which this study was performed. It first describes the experimental testbed and provides evidence that the base case used in later sections is sound, i.e., that it is representative of the behavior of production-quality TCP/IP implementations.
The hardware used for all tests consists of two DEC 3000/600 workstations connected over an isolated 10Mbps Ethernet. These workstations use a first-generation 21064 Alpha CPU running at 175MHz [93]. The CPU is a 64-bit wide, super-scalar design that can issue up to two instructions per cycle. Though the peak issue rate is two, there are few dual-issue opportunities in the pure integer code that is typical for systems code. Thus, as far as the networking subsystem is concerned, it is more accurate to view the CPU as a single-issue processor.
The workstation's memory system features split primary i- and d-caches of 8KB each, a unified 2MB second-level cache (backup-cache, or b-cache), and 64MB of main memory. All caches are direct-mapped and use 32-byte cache blocks. The d-cache is write-through, read-allocate. CPU writes to the b-cache are aggregated through a write-buffer that is four entries deep, with each entry holding a full cache-line. Writes to the write-buffer are merged, if possible. Since Alpha instructions have a fixed length of four bytes, an i-cache block size of 32 bytes implies that each block can hold eight instructions. Memory read accesses are non-blocking meaning that there is not necessarily a direct relationship between the number of misses and the number of CPU stall cycles induced by these misses. This is because non-blocking loads enable overlapping (hiding) memory accesses with useful computation. The memory system interface is 128 bits wide and the lmbench [63] suite reports a memory access latency of 2, 10, and 48 cycles for a d-cache, b-cache, and main-memory access, respectively. When executing code sequentially from the b-cache, the CPU can sustain an execution rate of 8 instructions per 13 cycles [34].
Unless noted otherwise, all software was implemented in a prototype version of Scout that was derived from the x-kernel [49]. The module graph consists of the networking subsystem and measurement code only. The resulting Scout system is so small that it fits entirely into the b-cache and, unless forced (as in some of the tests), there are no b-cache conflicts. All code was compiled using a version of gcc 2.6.0 [99] that was modified as necessary to support some of the techniques.
As the goal of this study is to test a set of latency improving techniques on protocol stacks that are representative of networking code in general, two protocol stacks are analyzed that differ greatly in design and implementation: a conventional TCP/IP stack and a generic RPC stack. TCP/IP was chosen primarily because its ubiquitous nature facilitates comparison with other work on latency-oriented optimizations. Due to their roots in BSD UNIX, the TCP/IP modules are relatively coarse-grained. In contrast, the RPC stack exemplifies the x-kernel paradigm that encourages decomposing networking functionality into many small modules [72].
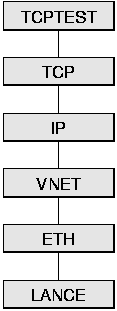
The module configurations for the two protocol stacks are shown in Figure 22. The left hand side shows the TCP/IP stack. At the top is TCPTEST, a simple, ping-pong style test program. Below are TCP and IP which are the Scout modules for of the corresponding Internet protocols [83, 82]. The TCP implementation is based on BSD UNIX source code so, apart from interface changes and differences in connection setup and tear-down, they are identical. Module VNET routes outgoing messages to the appropriate network adapter. In BSD-like networking subsystems, the functionality of VNET is implemented as part of the IP protocol. Module ETH implements the device-independent Ethernet protocol processing and module LANCE implements the driver for the Ethernet adapter present in the DEC 3000 machine.

The right hand side of Figure 22 shows the RPC stack. It implements a remote procedure call facility similar to Sprite RPC [110]. As the figure shows, the RPC stack is considerably taller than the one for TCP/IP. At the top is module XRPCTEST, which is the RPC-equivalent of the ping-pong test implemented by TCPTEST. Modules MSELECT, VCHAN, CHAN, BID and BLAST in combination provide the RPC semantics. A detailed description of the protocols these modules implement can be found in [72]. The modules below BLAST are identical to the modules of the same name in the TCP/IP stack.
To determine whether the base case is sound, the Scout prototype version of the TCP/IP stack is compared with the version implemented by DEC UNIX v3.2c. The latter is generally considered to be a well-optimized implementation and runs on the same platform as the Scout system. Because of large structural differences between the two, it is, however, not meaningful to directly compare end-to-end performance. For example, in DEC UNIX, network communication involves crossing the user/kernel boundary, whereas in the Scout prototype, all execution is in kernel mode. For this reason, the performance comparison concentrates on TCP/IP input processing. Functionality-wise, the two versions are essentially identical for this part of the network processing, so a direct comparison is meaningful. Since the interest is in processing latency, the case measured involves sending a one byte TCP segment between a pair of hosts.
The necessary data was collected by instrumenting both kernels with a
tracing facility that can acquire instruction traces of pristine,
working code.
| UNIX | Scout | |
| v3.2c: | v0.0: | |
| # of instruction executed... | ||
|
... from IP to TCP input: |
262 | 437 |
| ... from TCP to socket input: | 1188 | 1004 |
| CPI: | 4.3 | 3.3 |
Table 5 lists the instruction counts for TCP and IP input processing as well as the average number of cycles per instruction (CPI) achieved for the entire input processing. The first row in the table gives the number of instructions executed as part of IP processing, and the second row gives the number of instructions executed as part of TCP processing. For UNIX, IP processing includes all instructions executed between entering ipintr and entering tcp_input and for Scout this includes everything between ipDemux and tcpDemux. Similarly, for TCP processing under UNIX, everything between tcp_input and sowakeup is counted and for Scout everything between tcpDemux and clientStreamDemux is counted. The third row gives the average CPI for the entire TCP/IP input processing. It is the quotient of the execution times (in cycles) and the total instruction count.
As the first and second rows in Table 5 illustrate, DEC UNIX has a shorter IP processing while the Scout implementation has a shorter TCP processing. Overall, the two traces have almost the same length: 1450 instructions for DEC UNIX versus 1441 instructions for Scout. As the last row shows, the average number of cycles required to execute each instruction (CPI) is 3.3 for Scout and 4.3 for UNIX, so in terms of actual execution time, Scout is more than 20% faster. The important point, however, is that the similarity in code-path length suggests that the Scout TCP/IP is indeed comparable to production-quality implementations.