Modules are the unit of program development in Scout. In the Scout implementation, modules are actually called routers to encourage thinking of them as entities that route data through the system and also to avoid the overloaded term module. The flip-side of this convention is, of course, that the term router sometimes causes confusion when speaking of Scout in the context of communication networks that employ conventional network routers. Independent of the implementation, this dissertation continues to use the term module for the sake of consistency.
The choice of the granularity of modules is important since modularity is not free of costs. First, modularity often causes runtime overhead. Sometimes, the overhead is due to the limited context that is available when building the modules. For example, the programmer may not know in what context the module will be used and therefore is forced to implement the most general case, or independent compilation limits the context available to the compiler's optimizer, making it difficult to optimize across module boundaries. Second, modularity implies the use of standardized interfaces. These interfaces ensure that a large number of module pairs can be connected to form new and interesting systems. However, adhering to these relatively strict and difficult-to-change interfaces forces implementing modules in a way that is often suboptimal. For example, auxiliary data sometimes needs to be packaged into abstract data types to communicate them across module boundaries. Consequently, dividing up a system into the smallest possible modules is generally not a good idea. On the other hand, the extreme case of not using modules at all is certainly not ideal either since that would be equivalent to building a vertically integrated system.
Out of these considerations, a Scout module is expected to provide a well-defined and independent functionality. Well-defined means that there usually is either a standard, interface specification, or other existing practice that defines the exact functionality of a module. Independent means that each single module should, by itself, provide a useful, independent service. That is, the module should not depend on there being other specific modules connected to it. While Scout does not enforce these rules, they are assumed in the design. As a result, Scout works best when modules have an intermediate level of granularity. Typical examples are modules that implement networking protocols, such as IP, UDP, or TCP; modules that implement storage system components, such as VFS, UFS, or SCSI; and modules that implement drivers for the various device types in the system. Examples of modules that, for Scout, are likely too fine-grained include the IP fragmentation algorithm, the MPEG inverse discrete cosine transform, or the UDP checksumming algorithm.
Given that Scout claims to be able to avoid the disadvantages of modularity by using paths, it may be surprising that it does not advocate modules of the smallest possible granularity. The reason for this is two-fold. First, paths primarily address inefficiencies due to limited optimization context. It is distinctly more difficult to automatically avoid overhead that arises due to interface mismatches. Of course, it would be possible to manually implement an optimized path that avoids interface mismatches, but whenever possible, it is preferable that efficient paths be created automatically from the underlying modules. Second, there is also a third cost to modularity: the act of decomposing a system into modules takes time and consideration. If the resulting modules are so small that they can be used in only one possible module configuration (i.e., they cannot be reused), then nothing is gained. In other words, there is no advantage to going below a certain level of granularity.
Abstractly, a Scout module implements a certain functionality and provides access to this functionality through services. Each service provides access to one aspect of the module's functionality. For example, modules often provide filter-like functionality, which could be realized by a pair of services: one service representing the filter's input, the other the filter's output. However, the number of services provided is not limited to two, but is determined by the module. In the degenerate case, a module might not have any services at all, though such an isolated module would not be very interesting as it could not be connected to any other module. More typically, modules provide on the order of two or three services. The services in an module are assigned unique names to make it possible to reference and distinguish them. Other than the requirement that the names are unique, they can be arbitrary strings. Since services are accessed by other modules, they also have a type associated that specifies the protocol (language) that the service uses to communicate. The exact meaning of this type will be discussed later in this chapter. For now, it is sufficient to know that each service has a name and type associated with it.
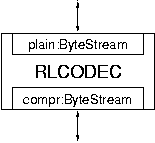
An example module is shown in Figure 11. The big box represents a run-length compression filter [91]. The two nested boxes represent services: plain provides access to the plain, uncompressed data and compr provides access to the run-length compressed data. Both services are of type ByteStream. As shown in the figure, it is customary in Scout to separate the service name from its type by a colon (a convention adopted from Pascal-like languages [20]). Suppose ByteStream represents a bidirectional stream of data bytes. In this case, data sent into the plain service would be run-length encoded and sent out through the compr service. Conversely, data sent into the compr service would be run-length decoded and then passed on through the plain service. This is the reason the module is called RLCODEC: it provides both run-length encoding and decoding functionality.
Concretely, a Scout module is implemented as a collection of C source files. Each module is described by a so-called spec file that lists the names of the C source files that belong to the module and the services that the module provides. The syntax for spec files is shown below:
module name {
files = {filename, ...};
service = {[<]name:type, ...};
}
module RLCODEC {
files = {rl-encoder.c, rl-decoder.c, rlcodec.h};
service = {plain:ByteStream, compr:ByteStream};
}
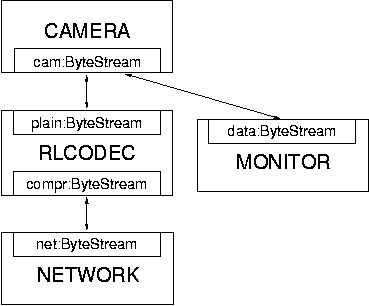
To form a complete system, individual modules need to be connected into a module graph. A module graph consists of a collection of modules whose services are connected in a (hopefully) meaningful manner. For example, to build a network-attached camera whose video data should be run-length encoded before being sent out on the network, one could use the module graph shown in Figure 12. In this graph, RLCODEC represents the run-length codec introduced earlier in this chapter, CAMERA is the device driver for the camera, MONITOR is a device driver for the small monitoring display of the camera, and NETWORK is the module implementing network support (in reality, the networking subsystem is likely to consist of multiple modules). Recall that a ByteStream is a bidirectional data streams, so in this simplistic example, commands that are sent from the network to the camera would have to be run-length encoded as well.
In Scout, the module graph of a system is described by the file config.graph. This file consists of a list of module declarations, followed by a list of connections. The two lists are separated by an at-sign (@). The syntax of this file is illustrated below:
In this description, iname represents an instance name, mname a module name, and sname a service name. The graph description distinguishes between the instance name and the module name to allow using the same functionality (module) in multiple places in the module graph. Instance names can be arbitrary strings as long as they are unique within a module graph. To keep the discussions in this dissertation simple, we generally will not distinguish between a module (a given functionality implemented by a collection of C files) and the instantiation of a module (the type of object that the module graph is composed of). Analogously, if the instance name of a module is omitted in a graph description file, the module name is used by default. In the graph description file, the binary operator <> represents a connection between the module/service pair mentioned on the left hand side, and the module/service pair on the right hand side.name=iname module=mname; ... @ iname1.sname1<>iname2.sname2; ...
module=CAMERA; module=RLCODEC; module=NETWORK; module=MONITOR; @ CAMERA.cam<>RLCODEC.plain; RLCODEC.compr<>NETWORK.net; CAMERA.cam<>MONITOR.data;
The graph shown in Figure 12 could be implemented by the graph description file shown in Figure 13. Most of the connections in this graph are straight-forward. Note, however, that the cam service of module CAMERA has been connected twice: once to the plain service of RLCODEC and once to the data service of MONITOR. In general, the number of connections allowed is both service and module dependent. The current implementation of Scout does not provide the means to express such constraints in the module's spec file, but modules can ensure at runtime that the correct number of connections have been made. This is the most flexible solution since the logic verifying the connection count can take into account all of the information available at runtime; e.g., the number of expected connections may very well depend on the number of connections made to another service of the same module. On the other hand, the experience gained so far suggests that most services expect either at most one, exactly one, at least one, or an arbitrary number of connections. Thus, supporting these constraints in the spec file would seem like a good idea since that would help to catch most configuration errors at system build time instead of at runtime. Moreover, this solution would not sacrifice flexibility: in the case where none of the four proposed constraints is perfectly appropriate, the service could specify arbitrary number of connections as the constraint in the spec file and perform the actual verification at runtime, as is presently done.
The semantics of multiply connecting the same service is also module dependent. In the case of the CAMERA module, it presumably would mean that video data is sent to both connections and that commands are accepted from either one. Multiple connections are commonly used by modules that do some form of multiplexing and demultiplexing among multiple data streams. Such modules essentially route data through the module.
Finally, as Figure 12 shows, a module graph often represents a layered system. That is, higher-level modules provide services that are implemented in terms of other, lower-level services. For reasons of flexibility, Scout does not, however, enforce strict layering. Cyclic module graphs are admissible as long as there is a partial (non-cyclic) order in which the modules can be initialized; more on this later.
A pair of services can be connected in the module graph only if they are compatible. For the purpose of compatibility testing, a service consists of a pair of interface names: the first element specifies the name of the interface that the service provides and the second element specifies the name of the interface that the service expects. Interfaces are explained in detail in Section 3.3, but for the purpose of this discussion, it is sufficient to think of an interface as a collection of (typed) routines that can be called by the user of the interface.
A pair of services is considered compatible if the interface provided by one service is compatible with the interface expected by the other service and vice versa. Suppose the ByteStream service had been declared like this:
This would mean that a service of type ByteStream provides an interface of type ByteStreamIface and also expects an interface of the same type. This implies that a ByteStream service can be connected to any other ByteStream service. Asymmetric services are of course possible. The most common asymmetric case is where a service provides an interface but does not expect any interface (or vice versa). This is used for connections in which communication can be initiated in one direction only.service ByteStream = <ByteStreamIface, ByteStreamIface>
The current Scout implementation does not check for compatibility in a module graph. Supporting this would again catch more configuration errors early in the lifetime of a system, namely during build time.
During build time, the module graph exists in the form of the config.graph description. Scout also provides an explicit representation of the module graph at runtime. This makes it possible to address connections in the graph by names that are computable at runtime (the names are actually integer indices). For example, the CAMERA module described earlier needs to send out the video data on all connections to its cam service. With a runtime representation of the graph, this can be achieved with a simple for-loop.
Each module m exports a global function called mCreate that creates and returns an object representing the module. The prototype for these functions is shown below:
Formal argument n specifies the instance name of the module and c is an array that specifies how many times each service has been connected to other services. The module creation function can verify the connection counts and, if correct, return the newly created module, or if incorrect, return NULL. The module creation functions are called by the Scout runtime system at boot time. The order in which the modules are created is unspecified.Module mCreate (String n, int c[]);
The value returned by the module creation function is a pointer to a C structure of the following type:
typedef struct Module {
String name;
String module_name;
long (*init)(Module m);
CreateStageFunc createStage;
DemuxFunc demux;
struct ModuleLink {
Module module;
int service;
} links[][];
} * Module;
As alluded to in the previous paragraph, the module initialization functions are called once the runtime version of the module graph has been created. To a first approximation, the order in which these functions are called is arbitrary. However, it is not uncommon that initialization of a module requires the invocation of services provided by other modules. In support of this, the initialization order can be constrained using the less-than marker described in 3.2.2. When a module is initialized, it is guaranteed that all modules connected through services that are marked in this way have already been initialized. In other words, the less-than marker imposes a partial order on module initialization. A valid module graph may not contain any cyclic dependencies in the module initialization order constraints.
An interesting question is whether the choice of C as the implementation language complicates the problem of realizing a modular system. If that were the case, then clearly a more appropriate language would be desirable. However, there is little reason to believe this to be true. For example, consider object-oriented languages. The main feature of Scout's module infrastructure is that it moves the point at which external interfaces are bound from the time a module is implemented to the time a system is configured (cf., Figure 10). With an object-oriented language, the same can be achieved by realizing each type of service as a separate class. Assuming modules are represented by their own class, then a module could be instantiated by passing one service object for each connection in the module graph. But in effect, this is just a slightly different implementation from the modular system described earlier. In other words, object-oriented languages do not, by themselves, provide a form of modularity that would be sufficient for Scout.
Just as important, a key challenge to building modular systems is to find and define an appropriate set of interfaces. There are two conflicting goals in selecting interfaces. On the one hand, an interface should be well-suited to the needs of a module. Otherwise, using the interface might be cumbersome and cause additional overhead for the module. On the other hand, if this were followed to the extreme, then every module might end up using its own interface, meaning that they could not connected in to a useful module graph. Note that this issue, too, is completely independent of the implementation language.
So, in summary, there seem to be few and only minor disadvantages to using a relatively low-level language such as C. A major advantage of C, as far as systems programming, is concerned is the transparency it affords: since it operates at such a low level, it is generally easy to guess what kind of machine code a given piece of source code translates into. This reduces the likelihood of small changes in the source code inadvertently leading to large performance differences. In this sense, using a language such as C improves predictability at the programming level. The biggest disadvantage of using C is likely to be found not in convenience-of-use issues, but in suitability for optimization. For example, high level functional languages such as SML are more amenable to aggressive optimization than C [8]. But the high level of abstraction that enables these aggressive optimizations is also the reason that makes such languages difficult to compile into code as efficient as C. As long as there is a performance differential on the order of a factor of two or more, C appears to be a more practical choice.
Another modularity issue worth discussing is that the Scout module graph is presently configured at build time and, hence, it is not possible to extend the graph at runtime. However, it is straight-forward to add a dynamic module-loading facility to Scout. The biggest issue in doing so is the security issue, not the actual dynamic loading. An alternative to extending the module graph at runtime would be to configure a virtual machine module into the graph that would allow interpreted code to be downloaded and executed inside Scout [39, 25].