This section discusses how Scout paths assist in three different resource management tasks: proper sizing of I/O-queues, proper scheduling of the CPU, and admission control.
As Figure 26 shows, the two queues of primary interest in a video path are the input queue in module TULIP and the output queue in module TGA. Both queues are unavoidable: fundamentally, the input queue is necessary because, for high-latency networks, multiple network packets may have to be in transit at any given time to be able to sustain the throughput needed by the video. If multiple packets are in transit, then, due to network jitter, these packets may all arrive clustered together and since the peak arrival rate at the Ethernet is much higher than the typical MPEG processing rate, the queue is needed to buffer such bursts. The output queue is also used to absorb jitter, but it does so at a more global level. First, decompression itself introduces significant jitter. Depending on the spatial and temporal complexity of a video scene, the encoded size of any particular video frame may be orders of magnitudes different from the size of the average frame in that stream. Second, the network itself may suffer from significant jitter, e.g., due to temporary congestion of a network link. The third jitter component is due to the sender of the MPEG stream. For example, the sender may read the video from a disk drive that may be accessed concurrently by other tasks.
Since there are queues in each path, an important resource management question is how big these queues should be. To conserve memory, it is clearly desirable to keep them as small as possible. This is particularly true for the output queue since each queue element consists of a complete video frame, which may be quite sizeable (225KB for a 320 × 240 RGB image). But on the other hand, the queues need to be big enough so that they can absorb most, if not all jitter normally encountered.
First, consider the input queue. If processing a single packet requires more time than it takes to request a new packet from the source, then an input queue that can hold two packets is sufficient: one slot is occupied by the packet currently being processed, and the second slot is advertised as free to the source. By the time the processing of the current packet has completed, the next packet will have arrived, and thus, the processor is never kept idle. On the other hand, if the roundtrip time (RTT) is greater than the time to process a packet, then the input queue needs to be two times the RTT × bandwidth product of the network. This relationship is easy to derive, but the intuition behind it is that several packets need to be grouped together so that the processing time of the packet group is at least as big as the roundtrip time. Then two slots for such packet groups are required to keep the network pipe full. This discussion implies that in order to properly size the input queue, it is necessary to know the relationship between the average roundtrip time and the average processing time per packet. The roundtrip time can be estimated, for example, with the algorithm typically used for TCP [50]. For example, in the protocol stack of NetTV, MFLOW could implement this by putting a timestamp in its packet header and making available this measured roundtrip time by maintaining a well-known path attribute (e.g., AVG_RTT), giving the measured average roundtrip time in micro-seconds. Keeping track of the path execution time is straight-forward as well, especially if the scheduler maintains a path attribute that specifies the total CPU time accumulated so far. If such is the case, the average packet processing time can be approximated by the amount by which the accumulated CPU time increases while processing a packet. With this setup, the Ethernet driver (TULIP) can simply test whether both the average roundtrip time attribute and the accumulated CPU time attribute are present in the path's attribute set. If so, it can use their values to compute the proper queue sizes and resize the queues accordingly. Note that the path plays two central roles in this application: first, it provides the means to communicate information (the roundtrip time from MFLOW to TULIP and the processing time from the scheduler to TULIP) and second, it enables accurate measuring of the per packet processing time (since the path extends all the way from the source device to the sink device).
In the case of the output queue, the factors influencing queue size are more varied and complex. In theory, it might be possible to compute an appropriate queue size based on recent observed history. However, the time-scales involved easily reach a range that is readily noticeable by a human user. Hence, a feedback based algorithm is likely too slow to be practical. In effect, this means that automatic control of this parameter requires either distributed paths or a network resource reservation protocol such as RSVP [11] (or a combination of both). For these reasons, Scout currently leaves this parameter under user control.
To guarantee proper scheduling, two properties must be satisfied. First, the system must always execute the highest-priority runnable path. In other words, priority inversion must be avoided. Second, the scheduling parameters (policy and priority) must computed properly for each path. Fortunately, paths assist in solving both problems.
In traditional systems, a frequent source of priority inversion is due to queues that are shared by distinct dataflows. For example, UNIX commonly uses a single queue for all IP packets. This can cause priority inversion since low-priority IP packets may have to be processed before a high-priority packet can be discovered and processed. Note that this problem cannot be solved simply by replacing the shared IP queue with a priority queue. This is because IP itself does not necessarily have sufficient information available to judge the priority of a packet. The Scout NetTV appliance can easily avoid this problem because each video path has its own input queue. With this setup, newly arriving packets are classified at interrupt time and then placed on the correct path queue.
Avoiding priority inversion is one of the more significant advantages of paths and can readily be demonstrated. Consider the case where a video is being played back on a remote machine. A malicious or negligent user could start sending ICMP ECHO requests at a high rate to the target system. Since each ICMP ECHO request triggers a corresponding reply, this can lead to a significant CPU load on the target system. In traditional systems such as Linux, where all arriving network packets have to go through a shared queue, this leads to priority inversion. Specifically, low-priority ICMP ECHO requests may appear in the shared IP input queue ahead of high-priority video packets. This causes traditional systems to spend too much time processing ICMP packets and too little time processing video packets. In contrast, no such priority inversion occurs in Scout since separate paths are used for handling video and ICMP packets.
The effect of priority-inversion is illustrated in Table 16, which shows how the maximum decoding frame rate for the Neptune video (see Table 15) drops when the ICMP load is added to the Scout and Linux systems, respectively. The additional load consists of a flood of ICMP ECHO requests. This load is generated using the UNIX ping -f command. This command either sends ECHO requests as fast as it receives replies or at a minimum rate of 100 packets per second. In other words, rather than a truly malicious user, it represents a user that attempts to send packets as quickly as possible as long as the target system can keep up with the stream of requests, but limits the sending rate to 100 packets per second if the system appears overloaded.
| Frame-rate [fps] | |||
| unloaded | loaded | \Delta | |
| Scout | 49.9 | 49.8 | -0.2% |
| Linux | 39.2 | 22.7 | -42.1% |
In the Scout case, the video path is run at the default round-robin
priority, whereas the path handling ICMP requests is run at the next
lower priority.
Paths also help ensuring that the right scheduling policy and priority is used to process video packets. The default Scout scheduler is a fixed-priority, round-robin scheduler. Since video is periodic, it seems reasonable to use rate-monotonic (RM) scheduling for MPEG paths [58]. With this approach, priorities are assigned in increasing order of frame rate and non-realtime paths are given priorities below those of any realtime path. However, for video, there are several reasons why earliest-deadline-first (EDF) scheduling more practical:
For these reasons, Scout supports EDF scheduling for videos considered important by the user. As alluded to previously, RM scheduling could work well in a system where the workload is static (known at system build time). However, in a dynamic system such as Scout, RM would most likely have to be approximated with a single or just a few priorities for realtime tasks. If so, it is easy to demonstrate the advantages of EDF scheduling. For example, using EDF scheduling, Scout can display 8 Canyon movies at a rate of 10 frames per second and a Neptune movie playing at 30 frames per second without missing any deadlines. The same load performs poorly when using a single round-robin priority for the realtime tasks: with an output queue size of 128 frames per video path, on the order of 850 out of 1345 deadlines are missed by the path displaying the Neptune movie. The reason for this is that the round-robin scheduler keeps allocating CPU time to the 8 Canyon movies as long as their output queues are not full, even though the Neptune movie may need the CPU more urgently. Of course, this particular example could be accommodated trivially by using two realtime priorities, but the point is that it is always possible to construct equivalent examples as long as the number of round-robin priorities is fixed.
The interesting part of EDF scheduling is how the deadline of video paths is computed. If path execution is the bottleneck, then the goal should be to keep the output queue as full as possible. This increases the chance that a video can be displayed without missed deadlines even if some frames transiently overload the CPU. On the other hand, if network latency is the bottleneck, then the deadline should be based on the state of the input queue. Since at any given time some number of packets (n) should be in the transit to keep the network pipe full, the flow control protocol implemented by MFLOW must be able to advertise an open window of size n. This means that the deadline is the time at which the input queue would have less than n free slots. This time can be estimated based on the current length of the queue and the average packet arrival rate.
Since the path provides direct access to both queues, the effective deadline can simply be computed as the minimum of the deadlines associated with each queue. Alternatively, the path could use the path execution time and network roundtrip time to decide which queue is the bottleneck queue, and then schedule according to the bottleneck queue only. The latter approach is slightly more efficient, but would require a clear separation between path execution time and network roundtrip time.
Would scheduling based on the input queue ever make a difference compared to scheduling according to the output queue? Since the two queues are connected by a path, whether a scheduling decision can take effect depends on the state of the other, non-bottleneck queue---output cannot be produced unless input is available and input cannot be processed unless there is space in the output queue. However, despite this dependency, scheduling according to the bottleneck queue would make a difference for video paths. This is because there is not a simple one-to-one correspondence between input packets and output frames. The MPEG module effectively processes and then buffers incoming packets until a full output frame has been reassembled. Thus, scheduling according to the input queue would tend to process packets as soon as they arrive, which would help to keep the network pipe full. In contrast, scheduling according to the output queue would tend to cluster packet processing since incoming packets would be queued up until an output slot becomes available. This clustering (batching) would improve the effectiveness of the memory system and therefore effectiveness of the CPU at a time when CPU cycles are at a premium---certainly a desirable property.
Paths are also useful to decide whether or not a new video path should be admitted to the system. Admission control involves testing whether sufficient resources are available for a new path. The primary resources of concern are memory, CPU cycles, and I/O bandwidth. Since each path has a unique id, it is trivial to account for memory consumption on a per-path basis. While, in general, it is difficult to predict memory requirements a priori, it is easy to create a path and let it execute as long as it remains within the memory constraints set by the admission policy. This is particularly practical since experience indicates that many paths require little or no dynamic memory allocation once they are fully established. Thus, should a path exceed its memory limits, this fact will typically be discovered during path creation time.
Deciding admissibility with respect to CPU load is more difficult since by the time CPU overload is detected it may be too late for corrective actions. MPEG encoded videos make the problem especially difficult since the decoding time per frame is highly variable. Fortunately, there appears to be a fairly good correlation between the average frame size in a video and the average decoding time per video frame.
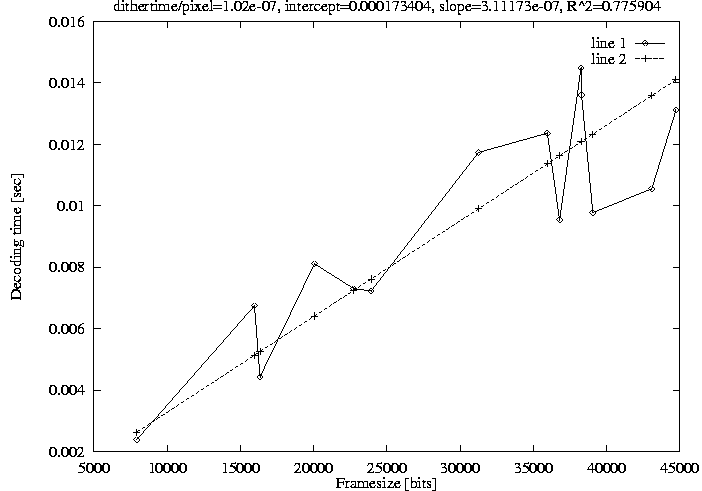
For example, the correlation for a selection of fourteen video clips is shown in Figure 27. The selection includes commercials, cartoons, and scenes from feature-length movies. The frame type sequences and graphical resolution also varies widely. The graph shows the average decoding time in seconds per frame as a function of the average frame size of each clip. Each data point is represented by a small diamond shaped marker and the sample points are connected by a solid line. In addition to this raw data, a linear regression curve is shown as a dashed line. The R2 coefficient of the linear regression through the fourteen sample points is only 0.78 and the graph shows that there certainly is quite some variability. On the other hand, it appears that the correlation is good enough to be useful for making at least a rough estimate as to whether a new video path could be accommodated or not.
The parameters of the linear regression depend on the CPU type, clock rate, cache sizes, graphics card, and so on, and are therefore highly system dependent. Rather than laboriously deriving the parameters for each platform, it would seem more appropriate to compute the parameters online as videos are being played back. This, again, is made easy by the fact that it is straight-forward to keep track of the per-path execution time.
Yet another path application comes into play when the admission control determines that a given video cannot be accommodated. At that point, a user may choose to view the video with degraded quality. For example, the user may request that only every third image be displayed. Thanks to ALF and early demultiplexing, this could be realized by a special classification filter that drops all packets except for those whose frame number is an integer multiple of three. In other words, paths make it possible to shed load at the earliest possible point within the system. Dropping the frames directly at the source may be an even better solution, but this is possible only if the video is transmitted point-to-point, not via multicast.
Admission control of the final resource of interest---I/O bandwidth---benefits from paths since device-to-device paths such as the video paths identify which devices are used. For video paths, the necessary network bandwidth and graphics adapter bandwidth can be computed relatively easily based on the geometric size of the video, its frame rate, and the average size of an encoded frame. Hence, to decide whether a newly created path should be admitted, the admission control policy would simply have to check whether enough bandwidth is remaining both for the source and the sink device of the path.