
Research
Anomaly Discovery Paradigm
 Staggering volumes of data sets collected by modern applications from financial transaction data to IoT
sensor data contain critical insights from rare phenomena to anomalies indicative of fraud or failure.
To decipher valuables from the counterfeit, analysts need to interactively sift through and explore the
data deluge. By detecting anomalies, analysts may prevent fraud or prevent catastrophic sensor failures.
While previously developed research offers a treasure trove of stand-alone algorithms for detecting particular
types of outliers, they tend to be variations on a theme. There is no end-to-end paradigm to bring this
wealth of alternate algorithms to bear in an integrated infrastructure to support anomaly discovery over
potentially huge data sets while keeping the human in the loop.
Staggering volumes of data sets collected by modern applications from financial transaction data to IoT
sensor data contain critical insights from rare phenomena to anomalies indicative of fraud or failure.
To decipher valuables from the counterfeit, analysts need to interactively sift through and explore the
data deluge. By detecting anomalies, analysts may prevent fraud or prevent catastrophic sensor failures.
While previously developed research offers a treasure trove of stand-alone algorithms for detecting particular
types of outliers, they tend to be variations on a theme. There is no end-to-end paradigm to bring this
wealth of alternate algorithms to bear in an integrated infrastructure to support anomaly discovery over
potentially huge data sets while keeping the human in the loop.
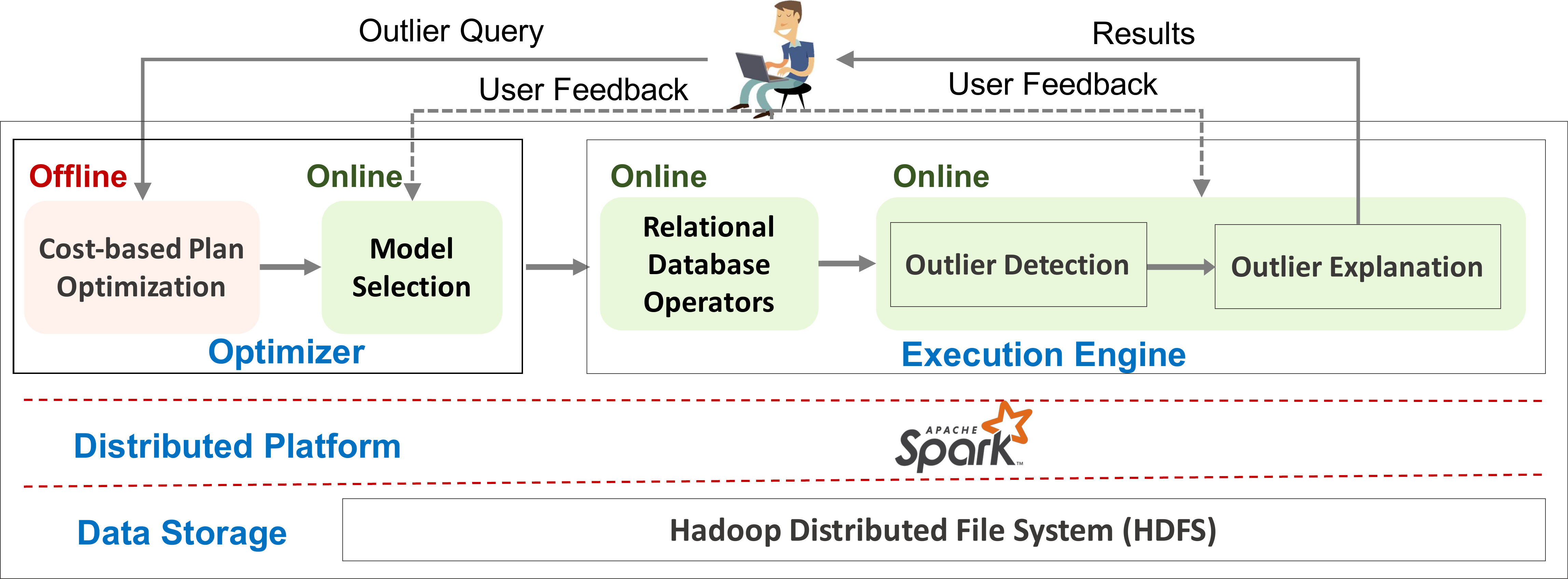
This project is the first to design an integrated paradigm for end-to-end anomaly discovery. This project
aims to support all stages of anomaly discovery by seamlessly integrating outlier-related services within
one integrated platform. The result is a database-system inspired solution that models services as first
class citizens for the discovery of outliers. It integrates outlier detection processes with data sub-spacing,
explanations of outliers with respect to their context in the original data set, feedback on the relevance
of outlier candidates, and metric-learning to refine the effectiveness of the outlier detection process.
The resulting system enables the analyst to steer the discovery process with human ingenuity, empowered
by near real-time interactive responsiveness during exploration. Our solution promises to be the first
to achieve the power of sense making afforded by outlier explanation services and human feedback integrated
into the discovery process.
This project is supported by NSF IIS and NSF CSSI.
AI for Data Curation and Data Curtion for AI
Data curation tasks that prepare data for analytics are critical for turning data into actionable insights. However, due to the diverse requirements of applications in different domains, generic off-the-shelf tools are typically insufficient. As a result, data scientists often have to develop domain-specific solutions tailored to both the dataset and the task, e.g. writing domain-specific code or training machine learning models on a sufficient number of annotated examples. This process is notoriously difficult and time-consuming.
We present SEED, an LLM-as-compiler approach that automatically generates domain-specific data curation solutions via Large Language Models (LLMs). Once the user describes a task, input data, and expected output, the SEED compiler produces a hybrid pipeline that combines LLM querying with more cost-effective alternatives, such as vector-based caching, LLM-generated code, and small models trained on LLM-annotated data. SEED features an optimizer that automatically selects from the four LLM-assisted modules and forms a hybrid execution pipeline that best fits the task at hand. To validate this new, revolutionary approach, we conducted experiments on 9 datasets spanning over 5 data curation tasks. In comparison to solutions that use the LLM on every data record, SEED achieves state-of-the-art or comparable few-shot performance, while significantly reducing the number of LLM calls
This project is supported by Amazon Research Award and NSF.
Unstructured Data Analysis
Modern organizations produce a large amount of unstructured documents. With the rise of Large Language of unstructured data like working with a relational database. Typically, these systems employ LLMs to generate structured tables from documents and analyze the generated tables with relational operations, such as selection, join, and aggregation. However, LLMs, which play a central role in such a system, are expensive both computationally and economically. Therefore, the LLM cost incurred during data generation constitutes the performance bottleneck of these systems.
To minimize this cost, we propose to build QUEST, a query optimizer that produces optimized execution plans for a given user query. Due to the properties of LLMs and unstructured data analysis, this query optimization problem raises unique challenges as opposed to that in relational databases. First, unlike database optimizers that merely minimize query execution time, the optimization objectives of QUEST are twofold: (1) minimize LLM cost and (2) guarantee high accuracy of data generation. Second, database optimizers collect some table statistics beforehand to estimate the selectivities and the cost of the operators. However, in unstructured data analysis, the tables are not available until running data generation operations. Clearly, generating these tables first and optimizing queries later will defeat the primary objective of QUEST. Moreover, the LLM cost of each data generation operation depends on the number of input tokens to an LLM. Therefore, to reduce the LLM cost, we should minimize the amount of text fed into an LLM. Relational databases use indexes to filter tuples that do not satisfy a predicate. However, in unstructured data analysis, given an input text, it is unsure whether an LLM could generate the desired data from it.
These challenges motivate our proposal to revisit the architecture and optimization principles of traditional database optimizers to achieve the objectives of QUEST. Rather than producing optimized plans before query execution, it adopts an optimize at execution time architecture that interleaving query optimization with execution, progressively estimates the cost of operations and dynamically optimizes plans, without assuming that the tables have to be available beforehand. It minimizes the LLM cost per data generation by offering an index style solution to reduce the amount of input text to LLMs, while guaranteeing the generation accuracy by interacting generation with filtering. It avoids generating tuples that will not be in the final query results, effectively minimizing the frequency of calling data generation operations. The ideas include reordering filters and joins, transforming joins to filters, and approximate aggregation queries on sampled pieces of text.
Optimizing Agentic Workflows for Data Management
Many applications are composing agentic workflows to solve data data management tasks, such as data preparation or text-based data analysis. These workflows are hard to compose, tune, and often slow and expensive. We thus propose to develop and end-to-end system that optimizes a agentic workflow.
Distributed/Cloud Databases
Build new cloud database architecture to fully resolve the performance and scaling issues, such as load imbalance caused by affinity-based scheduling and data locality issue.